NETFLIXのレコメンド構造を勝手に分解
Netflixのレコメンドはすごい。だって興味のあるものばかりレコメンドしてくれる!
先日、といっても少し前ですが「Netflixが「住所や年齢」を必要としないたった1つの理由」の記事を見つけて、そうそう必要ないんだよね。と思い、そういえばNetflixのレコメンドを分解してみたいんだった!ということで今回それを書いてみました。
さて、今回のこの紐解きですが、あくまで私が勝手にやっているもので、外側からの動作と知識による補完のため、特に内部事情も知らないのでその辺りはご了承ください。ただ、個人的にはかなり確度が高いと思っています。
レコメンドの基本構造
まずは、レコメンドの基本的なところを少しだけ触れますね。個々人に対してレコメンドやパーソナライズを構成する際は、どのデータを利用して、どうコミュニケーションをしていくかを考えて行く必要があります。
大きくはAttribution DataとIntent Dataの2つに分かれます。Attribution Dataとは「その人がどんな人であるか?」を表すもので、いわゆる属性ですね。性別や年齢、会員ランクなどがある場合はそういった部分もここに当てはまります。
Intent Dataとは、訪問者が「なぜそのサイトに訪問したか?」を表すデータで行動ベースでの内容を表すことが多いのですが「特定のカテゴリの閲覧」や「サイト内検索キーワード」「オンラインサーベイ」などになります。
これらデータは取得出来ている内容を活用しながらコミュニケーションに適用していくわけですが、優先度は画像のような感じで上から適用していくような感じになります。

Netflixのレコメンド構造は、閲覧データに全て基づくものです。つまり、Intent Dataをベースとしたものになっています。逆に言えばさきほど記載したリンクにもある通り、Attribute Dataは利用していないんですよね。
これはビジネス構造的に、扱っているものがエンターテインメントコンテンツであるため、コンテンツが閲覧することでその人の嗜好性が理解できるため、住所や年齢などなくても、その人の「ベースとなる興味」と「直近の興味」などわかるだけで良いんですよね。
これらをベースに「このコンテンツを見ている人は、このコンテンツも見ています」というものをベースにレコメンドを構成していくわけです。
プロフィールの利用
Netflixにはプロフィールを作成することが出来ます。家族など複数人で利用する場合に、それぞれプロフィールを分ける形になります。
これにより、それぞれのコンテンツの嗜好情報がかぶらないようになるわけです。KIDS向けのプロフィールなども作成可能ですが、まさに大人にとってはキッズコンテンツは必要ないですし、その逆で子供には大人向けのコンテンツは必要ない(見せたくない)わけです。
プロフィールを作成した直後はフラットな情報が並びます。これは最初は嗜好データがないからですね。TOPにレコメンド情報が並び、Netflixで人気の作品、Netflixオリジナル作品、話題の作品、ドキュメンタリー、アメリカTV番組・ドラマ、新作セレクション、TVコメディ、キッズ番組、ラブロマンス、など最上位のカテゴリが並ぶわけです。
ちなみにスマートフォンでは、プロフィールを新規で作成すると、いきなりフラットなコンテンツ画面が並びますが、PCでアクセスした場合は未閲覧の場合は好みの作品を選ぶダイアログが表示されます。
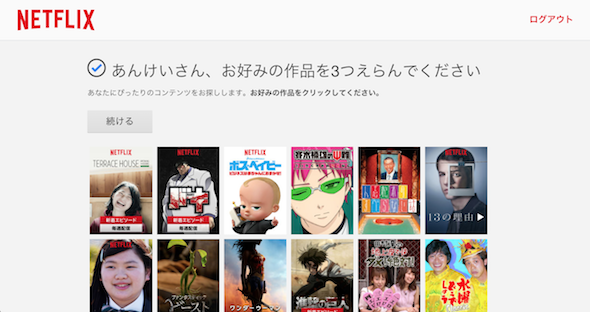
ここで選択した作品により、嗜好性を仮設定しレコメンドを構成するわけです。閲覧データが溜まるまでは、分からないのであれば聞いてしまえ、という感じですね。
コンテンツに紐づくデータ
そして最も重要なのがコンテンツに紐づく情報です。Netflixでは「Genre(ジャンル)」として管理されていますね。例えば下記のURLは「海外TV番組・ドラマ」になり、全てのジャンル情報は/genre/の下に固有の数字が付くURLを持っています。
https://www.netflix.com/browse/genre/1195213
各作品には大きく3つのグループの情報が紐づけられています。「出演」「ジャンル」「この作品は」といったものです。実際に下記に記載されているようなデータはそれぞれリンクが設定されています。
これらの「ジャンル」と「この作品は」はいずれもURL構造が「Genre」であり、実は同様のカテゴリ構造で管理されているようです。検索の画面などにも表示されるような大きなカテゴリが「ジャンル」として表示しており、「この作品は」はより嗜好性が高い情報となっています。

ちなみに「出演」については「Person」として別URLが作成されています。こちらはちょっと説明を入れ始めるとわかりにくくなるのでいったん割愛。
そして、基本はこのコンテンツに紐づくこれらデータを基にレコメンドが構成されている形になっています。
データとしては「閲覧されたコンテンツに紐づくジャンルタグ」「マイリストに追加したコンテンツのタグ」「コンテンツのGood/Bad評価」を参考情報にしていると思います。ただ、ここはあくまで想像。でも恐らくそうかと。
二重構造のレコメンド
Netflixのレコメンドは利用している側からすると、「そうそうこう言うの見たかったんだよね」から「へぇ、こういうのもあるんだ」といった発見もあったりします。この辺りは本当にうまい構造だなぁと思いました。
Netflixのレコメンド構造は、だるま落としのような形で、帯を積み上げた構造が大上段としてあります。これはPC版、App版ともにそのような形になっています。
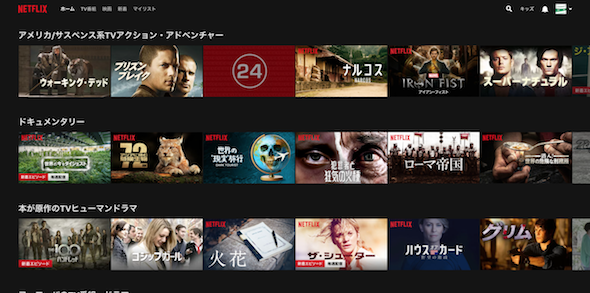
実はこれがかなり重要で、先程のコンテンツの閲覧などの情報をもとに、紐づくタグを利用して、帯のレコメンドが決定しています。閲覧が浅い場合は「ジャンル」で管理される大枠のタグ情報が反映されます。
これが閲覧が進むと「この作品は」に紐づくより詳細なタグ情報により、この帯情報が決まってくるわけです。帯の情報が決定するとあとはそのタグに紐づく「そのタグに絞ったこのジャンルの作品を見ている人はこれを見ている」を表示していくわえです。帯とその中という二重構造になっているわけです。
NetflixのTOP画面を眺めていると、同じ作品が何回か表示されることがあると思いますが、これは帯のタグ情報は被らないように制御されているものの、帯の中で表示されるコンテンツは、その帯に紐づく情報として表示されているので、そうなるんですよね。
また、表示される「帯」ですが下記のようなものがあります。
- マイリスト
- Netflixで人気の作品
- 視聴中のコンテンツ
- Netflixオリジナル作品
- 新着
- コンテンツに紐づくGenre(ジャンル・この作品は)の情報
- 特定の作品の閲覧に基づく
- もう一度見る
これらの帯をうまく組み合わせていくことで、「そうそうこう言うの見たかったんだよね」と「へぇ、こういうのもあるんだ」をうまく実現しているんですよね。

ちなみに初回に聞くものについては、データが溜まってくれば破棄されていると思います。あくまで直近のデータなどを基に組み立てていく感じになっているわけです。
また、固定で入っている帯の順番もたまに変わる(気がしている)ので、その辺りはランダム?で入れ替えてさらに新鮮さをだしていそうな気がします。
まとめ
これ以外にNetflixは様々なテストを絶えず行っています。今回はレコメンドに絞ったものにしたので、こちらは割愛しますが、各コンテンツのカバー画像などもテストしていたりもするようですね。
今回のレコメンドの構造ですが、おおよそは恐らくそれほどズレていないと思いますが、とはいえ細かいパラメータ調整やテストなどは実施されているとも思います。また、おおよその考え方として外からあくまで想像したというところにご留意ください。
ちなみにコンテンツごとに「マッチ度」が表示されますが、あれは恐らく、直近の興味のあるメタ情報からマッチ度を出しているだけで、あまりレコメンドには利用されていない感じがしました。(細かくは調査してません)
そして基本構造の考え方はNetflixのようなエンターテインメントコンテンツだけではなく、メディアやECサイトでも十分に活用できます。そして、コンテンツに紐づくメタデータ(いわゆるタグ情報)がきちんと整備されていれば、意外と実現できたりします。
ロジックをベースにテストを繰り返していくことで、いわゆる個人情報なんてなくとも十分にその人に合った情報は出していくことは可能です。ぜひ皆さんも良いレコメンドライフを!
追記:2018/09/10
ちなみに上記のエントリはあまり雑念を入れたくなかったので、事前情報収集はほどほどにしたのですが、改めて調べたところNetflixのABテストについてなど非常に良いエントリもありましたのでそちらも併せてぜひ。
- ケーススタディ:NetflixはどのようにA/Bテストを実施しているのか? | UX MILK
- This is how Netflix’s top-secret recommendation system works | WIRED UK
2つめのは英語ですがレコメンドとAIについて触れられています。基本構造としてのレコメンドは↑に書いている通りですが、最終的な「どのタグを優先するのか」といった部分はAIにより処理をするといった感じですね。


